 Multi-Set Inoculation framework
Evaluating Concurrent Robustness of Language Models Across Diverse Challenge Sets
Multi-Set Inoculation framework
Evaluating Concurrent Robustness of Language Models Across Diverse Challenge Sets
Multi-Set Inoculation Framework
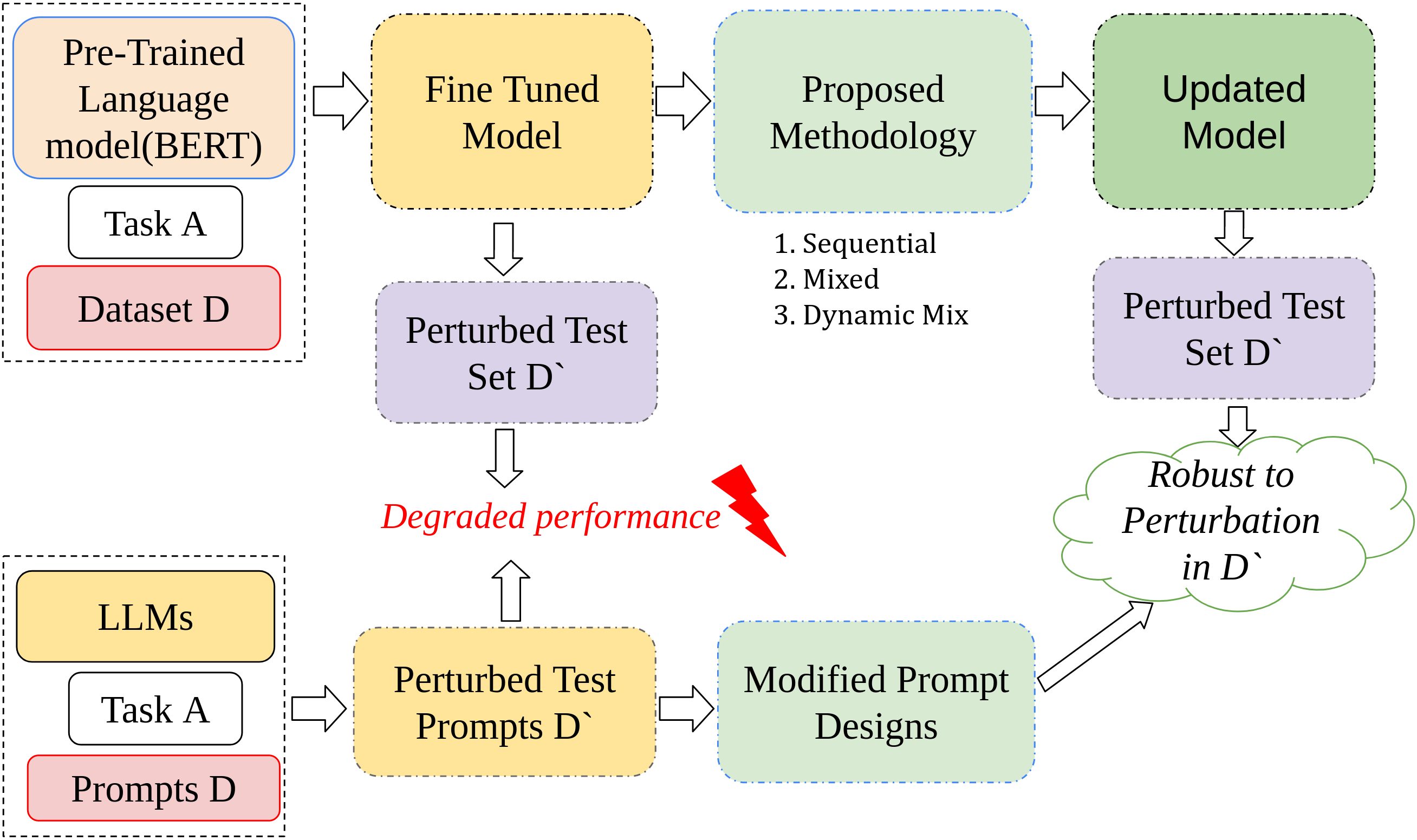
High-level flowchart describing the proposed frameworks for Pre-Trained Language Models (via fine-tuning) and Large Language Models (via prompt designing) on the pertrubed version of the
InfoTabs
dataset

Multi-Set Inoculation Framework
|
|
||
|---|---|---|
| 1 | Written | Takahiro Arai |
| 2 | Publish | Shogakukan |
| 3 | Eng. Publish | SG. Shogakukan Asia |
| 4 | Demographic | Shonen |
| 5 | Magazine | Weekly Shonen Sunday |
| 6 | Orig.Run | Mat 9,2018 - present |
| 7 | Volumes | 2 |
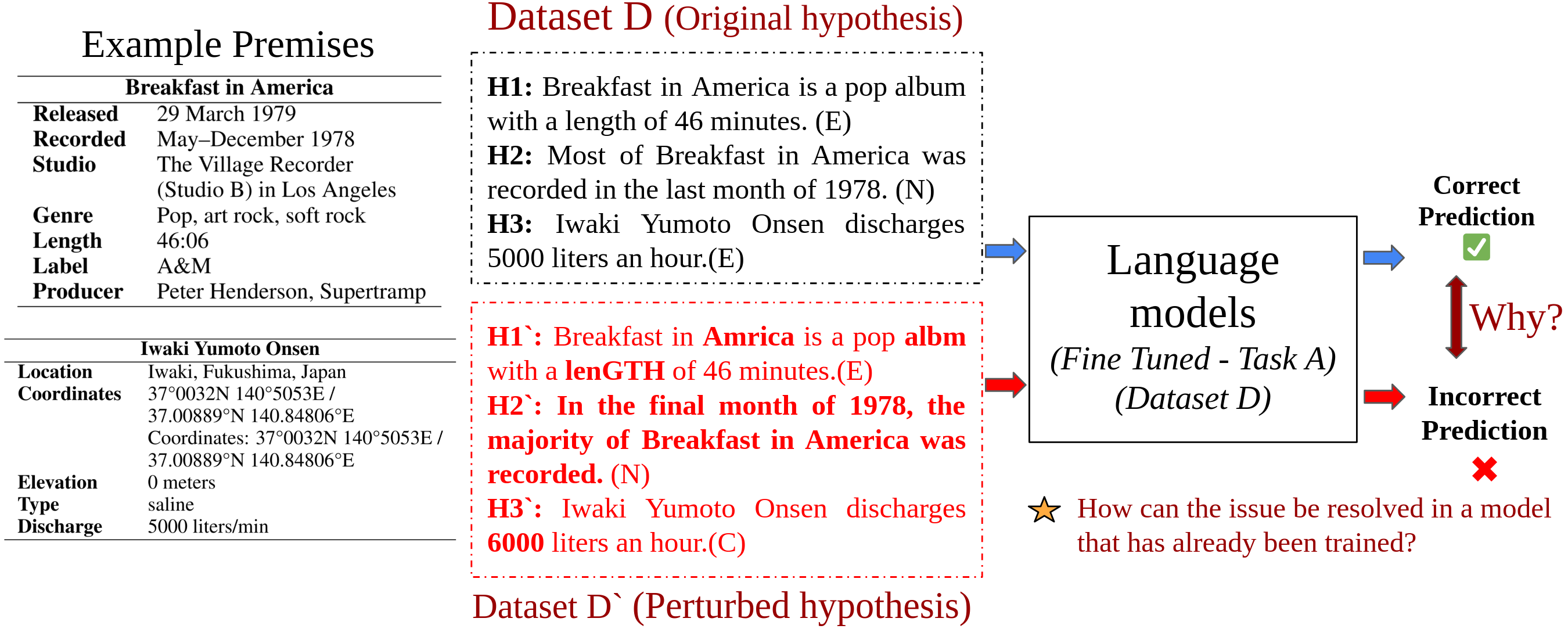
H
1
:
Takahiro Arai wrote
‘Case Closed’
comic series.
(Entailment)
H'
1
:
Takahiro Arai wotte
‘Case Closed’
comci series.
(Entailment)
H
2
:
‘Case Closed’
is a long-term comic series.
(Entailment)
H'
2
:
‘Case Closed’
isn’t a long-term comic series.
(Contradiction)
H
3
:
‘Case Closed’
became the anime Detective Conan.
(Neutral)
H'
3
:
Detective Conan is
‘Case Closed’
anime version.
(Neutral)
H
4
:
‘Case Closed’
has run over 5 years.
(Entailment)
H'
4
:
‘Case Closed’
has run over 10 years.
(Contradiction)
H
5
:
Shogakukan Asia published
‘Case Closed’
(Eng.).
(Entailment)
H'
5
:
Shogakukan UK published
‘Case Closed’
(Eng.).
(Contradiction)
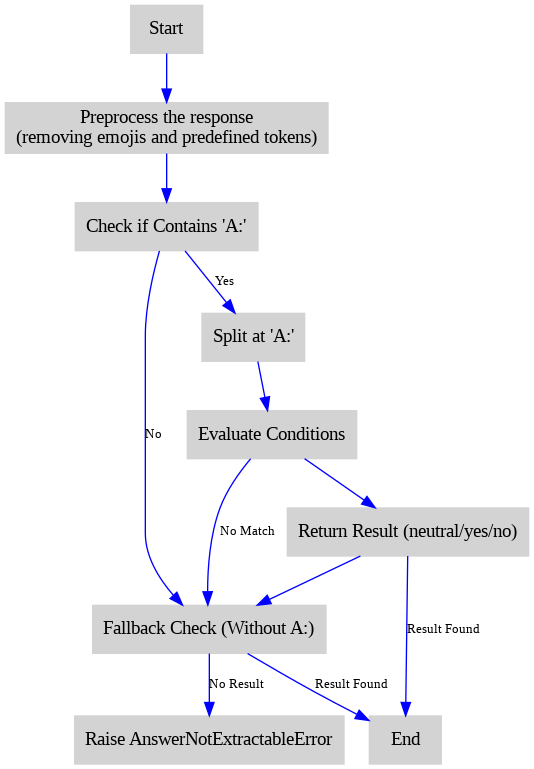
Answer Extraction Module outline
High-level flowchart describing the answer extraction procedure used to extract label
InfoTabs
dataset
Language models (LMs)
, often characterized by their black-box nature, can suffer from hallucinations and exhibit sensitivity to
input perturbations
, raising significant concerns about their trustworthiness.To address these concerns, it is crucial to develop a comprehensive understanding of the
failure modes
of these models and to devise strategies that improve their robustness and reliability. In this study, we introduce the
Multi-Set Inoculation Framework designed to assess the impact of input perturbations on models of various scales, including both pre-trained models and Large Language Models (LLMs)
.
Through the use of fine-tuning techniques , we aim to improve the model's robustness against such perturbations. We also investigate whether exposure to one type of perturbation affects the model’s performance on other types, either positively or negatively. To enhance robustness across multiple perturbations, we propose three distinct fine-tuning strategies . Furthermore, we extend our approach to LLMs by employing a Chain of Thought (CoT) prompting method , augmented with exemplars. We demonstrate the effectiveness of our proposed strategies using the Tabular-NLI task, showcasing how a well-trained model can effectively handle diverse input perturbations while maintaining high accuracy on the original dataset.
MSIN-Infotabs Dataset
The dataset utilized in this study is InfoTabs, a tabular-NLI dataset introduced by Gupta et al. InfoTabs encompasses a wide range of table domains, categories, and keys, showcasing diverse entity types and structures. Additionally, adversarial perturbations have been applied to InfoTabs, resulting in three test splits: α1 (original test set), α2 (adversarial set), and α3 (zero-shot/out of domain set).
Perturb Challenge Datasets are created incorporating perturbations derived from previous studies, augmented using various tools, along with manual adjustments. Each perturbation targets the hypothesis of an input sample, and challenge sets of up to 1,500 samples per perturbation type are curated.
To ensure diversity, a selection process is employed when the number of pertinent samples exceeds 1,500. Perturbations are categorized into five types: Character-level (C), Negation-type (N), Numeric (M), Location (L), and Paraphrasing (S).
Multi-Set Inoculation Framework
(MSIN)is hence developed to analyse concurrent robustness across these types of perturbations
| Short Code | Type | Description |
|---|---|---|
| Char/C | Character perturbation | Introducing random characters,switching characters, removing a random character, and substituting a random character in the randomly selected word. |
| Neg/N | Negation | Takes the negation of the statement and hence transforms entailment into a contradiction by negating the given sentence, keeping neutrals intact. |
| Num/M | Numeric | Changes a number within the the statement to another random number. |
| Loc/L | Location | modifies the identified locations (countries, cities, and nationalities) in a sentence to another place specified in the location map. The NER model (TextAttack) identifies the location in a given sentence and replaces it with a sampled location from a dictionary. Here, cities are replaced with other cities and similar changes for countries |
| Stan/S | Paraphrasing | paraphrases the given sentences without the loss of meaning using manual paraphrasing and Pegasus model. |
Strategies Proposed for analysis
The study employs Tabular-NLI to evaluate concurrent robusteness on a rather tough task and investigates how models like BERT, RoBERTa, GPT-3.5, and others respond to perturbations in natural language inference tasks.
The study introduces three fine-tuning strategies aimed at improving language model robustness across various input perturbations:
In this approach, the language model is fine-tuned on one type of perturbation at a time in a predetermined order. This sequential training can lead to catastrophic forgetting, where the model may lose the knowledge gained from earlier perturbations as it continues training on new ones.
This strategy fine-tunes the model on a combined dataset that includes samples from all perturbation types. A fixed number of examples from each perturbation set are selected, ensuring the model is exposed to diverse types of input disturbances during the training process. This approach aims to build a more generalizable model without sacrificing performance in specific perturbation areas.
Dynamic Mixed-Training builds on the mixed-training approach by adjusting the number of training samples from each perturbation set based on the model’s baseline performance. More challenging perturbations receive more training examples, making this a data-efficient strategy that focuses more heavily on the model’s weaknesses.
For large language models, we develop similar strategies drawing parallels to the strategies proposed for PLMs we analyze the different structures in prompts while devising the strategies
The model is provided only the task description without examples or prior knowledge of input perturbations
This method includes task examples with reasoning chains, enabling the model to learn and apply structured thinking to perturbation handling
Prompts explicitly instruct the model about specific perturbations, priming it to anticipate different types of noisy inputs
We hence propose the following techniques to make LLMs more adaptable and resilient to concurrent perturbationsIn the OPZS method, the model is provided only with a task description and no examples. This approach tests the model’s inherent ability to handle input perturbations without prior context or guidance.
In the OPCOT approach, the prompt is enriched with a few-shot strategy, offering task examples along with reasoning chains (exemplars). This helps the model improve its reasoning capabilities and better address complex tasks involving perturbations.
SEMP involves creating individual prompts for specific perturbations. Each prompt includes a task description, an explanation of the perturbation, and a corresponding exemplar, helping the model handle specific input changes effectively.
MESP combines multiple perturbation types into a single prompt. The model is presented with several examples from different perturbation sets in one prompt, allowing it to generalize across a variety of input changes while balancing between detailed explanations and exemplar diversity.
Multi-Set Inoculation framework
Experiment ResultsThe Analysis section of the paper presents a comprehensive evaluation of the impact of various fine-tuning strategies on language models when subjected to input perturbations. The findings indicate that single-set inoculation, which involves fine-tuning a model on one specific type of perturbation, generally leads to marked improvements in performance for that particular perturbation. For instance, models fine-tuned on negation perturbations exhibited a significant increase in accuracy, with improvements reaching as high as +25 points. However, this method often results in a trade-off; robustness against other types of perturbations diminishes, highlighting the challenge of overfitting to a single perturbation type.
| Train/Test | α1 | α2 | α3 | char | neg | num | loc | stan |
|---|---|---|---|---|---|---|---|---|
| baseline | 72.72 | 64.83 | 62.33 | 57.30 | 46.90 | 67.20 | 70.20 | 67.10 |
| char | 75.28 | 63.83 | 63.33 | 59.20 | 43.70 | 64.30 | 66.00 | 68.30 |
| neg | 66.94 | 64.56 | 58.06 | 52.80 | 71.90 | 69.60 | 69.70 | 62.40 |
| num | 62.06 | 60.83 | 52.50 | 47.30 | 69.60 | 85.40 | 83.00 | 57.60 |
| loc | 55.78 | 58.67 | 49.67 | 47.40 | 53.90 | 84.60 | 86.10 | 53.50 |
| stan | 73.56 | 62.61 | 60.44 | 58.30 | 40.80 | 70.30 | 67.80 | 66.80 |
In contrast, the multi-set inoculation strategy, particularly through the use of mixed training (MIX) and dynamic mixed training (DYNMIX), showcases a more holistic approach to model robustness. The mixed-training strategy integrates samples from various perturbation sets, allowing the model to develop a more generalized understanding of input variations. Dynamic mixed training further enhances this by varying the number of samples drawn from each perturbation based on the model’s baseline performance, thus focusing more on challenging perturbations that require additional training. Results indicate that these strategies consistently outperform sequential training (SEQ), which often leads to catastrophic forgetting, where the model loses previously learned information when exposed to new perturbations.
Additionally, the analysis emphasizes the performance of large language models (LLMs) such as GPT-3.5 and LLaMA-2, which demonstrate improved accuracy when utilizing few-shot prompting techniques, particularly those that incorporate Chain of Thought (CoT) reasoning. The study also notes that prompts designed to be aware of specific perturbations further increase the models’ adaptability to novel input changes. These findings underscore the importance of employing multi-set inoculation techniques and tailored prompting strategies to achieve greater robustness in language models across diverse perturbation scenarios.
Results on the
MSIN-InfoTabs dataset
Results on the
MSIN-InfoTabs dataset
Results on the
MSIN-InfoTabs dataset
Results on the
MSIN-InfoTabs dataset
Results on the
MSIN-InfoTabs dataset
@inproceedings{gupta-etal-2024-evaluating-concurrent,
title = "Evaluating Concurrent Robustness of Language Models Across Diverse Challenge Sets",
author = "Gupta, Vatsal and
Pandya, Pranshu and
Kataria, Tushar and
Gupta, Vivek and
Roth, Dan",
editor = "Al-Onaizan, Yaser and
Bansal, Mohit and
Chen, Yun-Nung",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-main.1237",
pages = "22162--22184",
abstract = "Language models, characterized by their black-box nature, often hallucinate and display sensitivity to input perturbations, causing concerns about trust. To enhance trust, it is imperative to gain a comprehensive understanding of the model{'}s failure modes and develop effective strategies to improve their performance. In this study, we introduce a methodology designed to examine how input perturbations affect language models across various scales, including pre-trained models and large language models (LLMs). Utilizing fine-tuning, we enhance the model{'}s robustness to input perturbations. Additionally, we investigate whether exposure to one perturbation enhances or diminishes the model{'}s performance with respect to other perturbations. To address robustness against multiple perturbations, we present three distinct fine-tuning strategies. Furthermore, we broaden the scope of our methodology to encompass large language models (LLMs) by leveraging a chain of thought (CoT) prompting approach augmented with exemplars. We employ the Tabular-NLI task to showcase how our proposed strategies adeptly train a robust model, enabling it to address diverse perturbations while maintaining accuracy on the original dataset.",
}



